「计算机基础」多CPU架构演进
昨天和前天通过文章《「计算机基础」CPU历史之AMD系列》和《「计算机基础」CPU历史之Intel系列》介绍了Intel和AMD的产品,今天围绕的话题仍然是CPU。
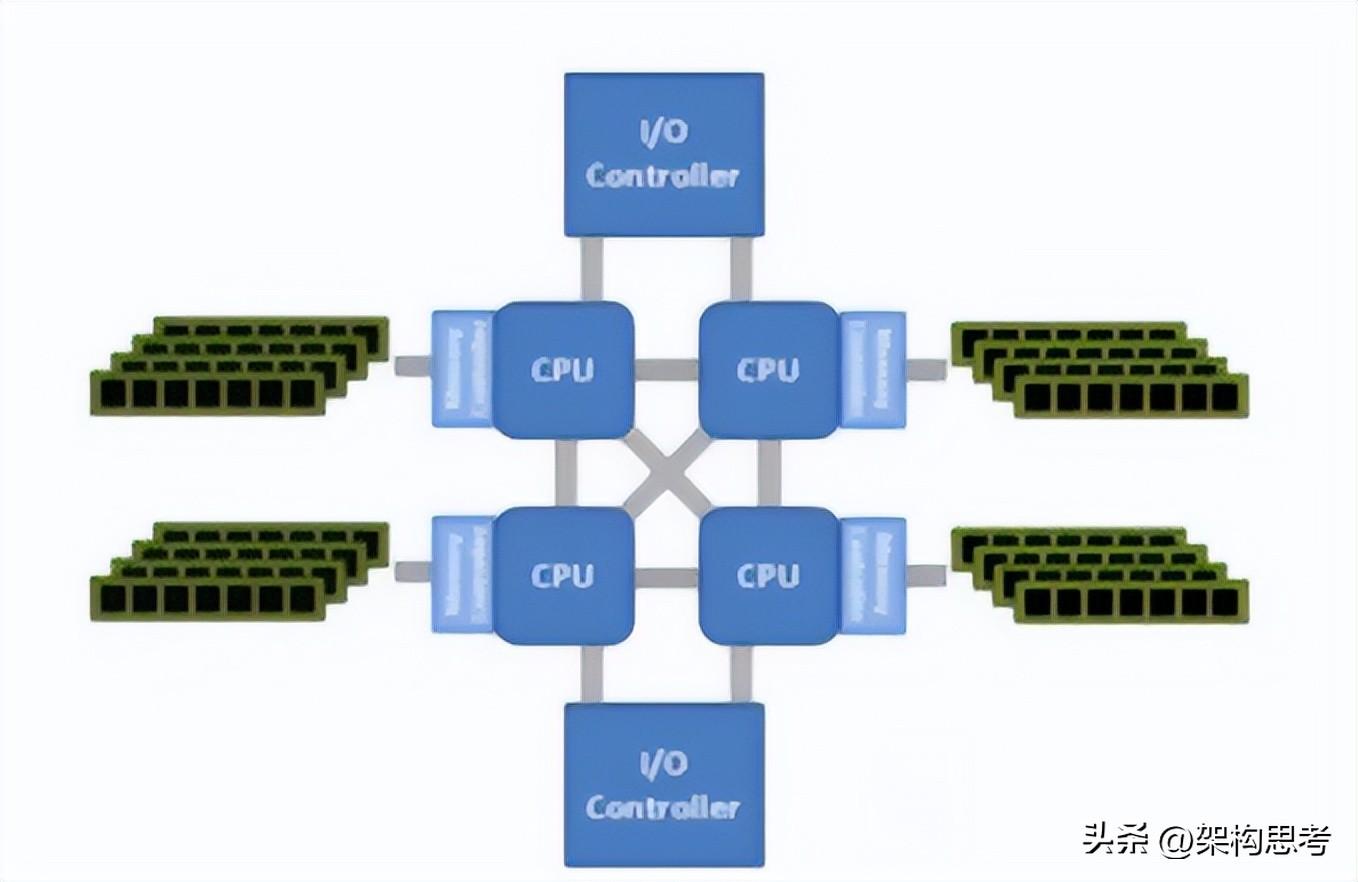
服务器最开始的时候是单CPU,然后才进化到了双CPU甚至多CPU的SMP架构。所谓SMP架构指的是多路CPU无主次,共享内存、总线、操作系统等。此时每个CPU访问内存任何地址所耗费的时间是相等的。所以也称为一致存储器访问结构
大家共享同样的内存,所以扩展能力有限,因为CPU数量增加了,内存访问冲突也会增加。为了进一步提高CPU数量的同时还能保证效率,NUMA架构出现了,将多个SMP进行松耦合。
还有一种AMP架构,不同的CPU是做不同的事的,互不干扰。
NUMA架构中,多个SMP通过Crossbar switch交换矩阵进行互联。
每个SMP有自己的内存,同时还可以访问其他SMP的内存,但是需要经过高速交换矩阵,很显然SMP访问自己的内存速度非常高,但是访问远端的SMP的内存还需要经过交换矩阵,延迟增加,可以看出NUMA通过牺牲内存的访问时延来达到更高的扩展性。

总之,SMP与NUMA架构对软件程序方面影响扩展性不大,一台主机内都使用单一的操作系统。
缺点是CPU数量增加,访问远端内存的时延也会增加,性能不能线性增加。此时MPP架构就出现了。
MPP说白了就是将多台独立的主机组成集群。显然在此架构下,每个节点都有各自的CPU、内存、IO总线、操作系统,完全松耦合。最关键的是MPP集群中的软件架构也相应的改变了,这样MPP的效率随节点数量增加就可以线性增加了。
其实如果NUMA架构下,如果通过上层软件来使得程序尽量少的读取远端的内存,NUMA效率也会线性增加。但是实际上NUMA操作系统仍然是同一个,内存仍然是全局均匀的,所以访问远端内存是不可避免的。
那么MPP相当于把内存强制分开,同时又改变了程序架构,这样就可以保证海量计算下的效率线性增加。
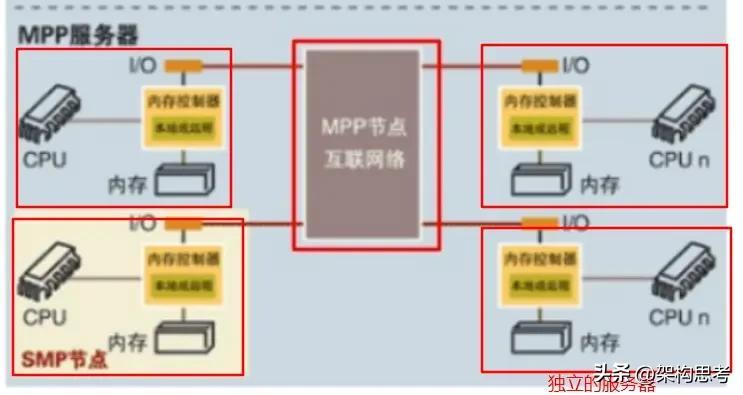

存储系统与服务器CPU架构演进相同,控制器就好比CPU,后端磁盘柜就类似于内存。
SMP
纵观存储系统的演进,一开始是单控,后来演进到双控互为备份,此时就类似于AMP,两个控制器各自处理自己的任务。
然后进入到双控并行处理的时代(HDS的AMS2000存储系统),类似于SMP,两个控制器可以并行的处理。
再到后来则有多控并行对称处理架构,Oracle的RAC集群就可以视为一种多点SMP,各种共享底层存储的集群文件系统都属于多点对称SMPNUMA
同样NUMA也出现在了存储系统中,比如EMC的V-Max相当于多个SMP利用高速交换矩阵来共享访问每个SMP上的内存,其中SMP就是一对控制器组成的Director,高速交换矩阵就是RapidIOMPP 那么IBM的XIV就属于松耦合MPP架构,每个节点都有自己的CPU、内存、IO接口,使用外部的交换机互相通信。 而HDS的VSP更像是一个紧耦合的MPP。 另一种属于MPP架构的存储系统就是分布式文件系统,比如HDFS等。
MPP对软件架构变化很大,所以传统存储厂商很难将之前的架构演进到MPP上来。

SMP/NUMA/MPP其实都算Scale-out,只不过程度和形态不同。
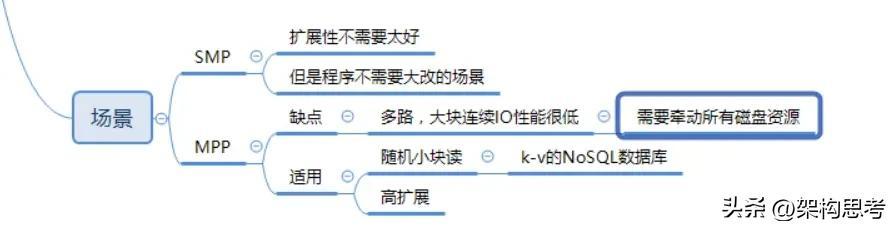
MPP架构的存储,比如XIV,在多路大块连续的IO下,效率反而很差。这是因为单路IO可能导致整个MPP集群中的磁盘资源全部牵动
但是如果是小块随机的IO,多路IO关联很少,则性能随节点数增加线性增加,这就好比将一个程序并行分解为多个子任务(类似于随机小IO),因为子任务之间的关联很少,节点之间的通信量很小,则并行执行的效率高。也就是MPP自身是share-Nothing架构,运行在上面的程序也尽可能的是Share-Nothing
SMP、NUMA、MPP各有各的好处,比如
SMP适用于扩展性要求不高,而又不想程序改变太大的场景。MPP则适用于海量数据下的高扩展性需求场景。它需要对程序进行大量的改变,而且多流大块连续IO场景下性能不佳。所以MPP架构广泛的应用于互联网的底层Key-Value分布式数据库,这种数据库主要应对高随机小块读的场景,可以获得非常高的性能。
文章来源:dy2903_https://www.cnblogs.com/dy2903/p/8341268.html


 0001
0001- 0002


 0000
0000

 0000
0000

 0000
0000
