【大语言模型|ChatGPT】搭建「英文案例翻译/分析机器人」实践
本章详细剥析如何搭建「自定义知识库的聊天机器人」。
机器人基本原理:
将现有资料喂给AI,让它用来回答问题或给出延伸建议等。
 传文档给AI,然后 AI 仅用该文档来生成合适的答案
传文档给AI,然后 AI 仅用该文档来生成合适的答案
操作步骤:S1. 导入Github 数据(导入几份流行营销案例,且案例都是英文)git clone https://github.com/Airbangs/Operation-management-case-baseS2. 安装依赖库pip3 install gpt-index
pip3 install langchain
pip3 install transformers
缺啥补啥S3. 编写脚本
num_outputs :设置最大的输出 token 数,若想回答问题的字数越多就设置越大。
Temperature:控制模型生成结果的随机性。温度越低,结果越确定,但也会越平凡或无趣。若要出人意料的回答,则将该参数调高一些。若想基于事实,如数据提取、FAQ 场景等,调成 0最合适。#!/usr/bin/env python3
from gpt_index import SimpleDirectoryReader, GPTListIndex, readers, GPTSimpleVectorIndex, LLMPredictor, PromptHelper,ServiceContext
from langchain import OpenAI
import sys
import os
from IPython.display import Markdown, display
import PyPDF2
# 设置 OpenAI API Key
os.environ["OPENAI_API_KEY"] = "你的Open_Api_Key"
def main():
# set maximum input size
max_input_size = 4096
# set number of output tokens
num_outputs = 4000
# set maximum chunk overlap
max_chunk_overlap = 20
# set chunk size limit
chunk_size_limit = 600
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.5, model_name="text-davinci-003", max_tokens=num_outputs))
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
documents = SimpleDirectoryReader('你的文件目录/files').load_data()
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index = GPTSimpleVectorIndex.from_documents(
documents, service_context=service_context
)
index.save_to_disk('index.json')
index = GPTSimpleVectorIndex.load_from_disk('index.json')
while True:
query = input("小朋友你是不是有很多问号,提出来让我帮你吧:")
response = index.query(query, response_mode="compact")
print(f"Response: <b>{response.response}</b>")
if __name__ == '__main__':
main()S4. 用中文总结英文案例内容
 尝试总结PDF内容
尝试总结PDF内容
S5. 提问
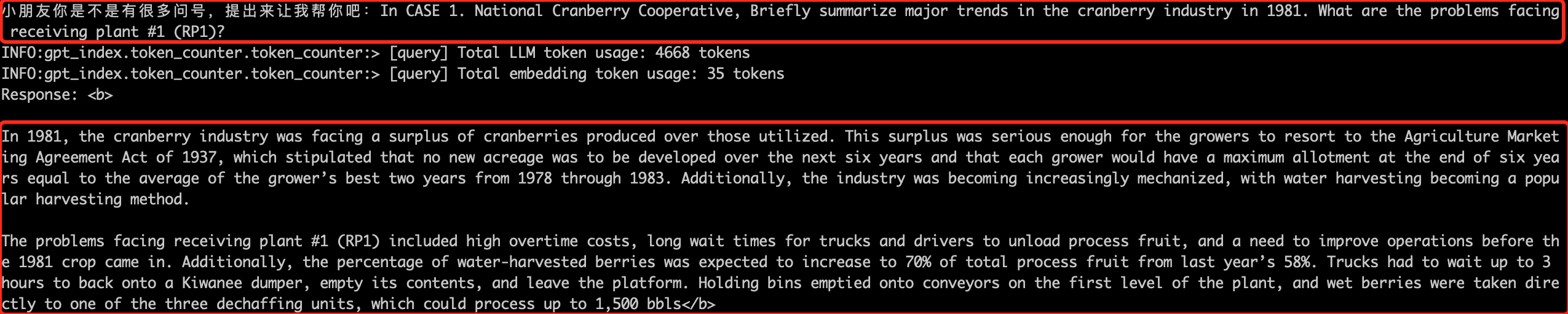 回答时默认语言会受提问所使用语言影响
回答时默认语言会受提问所使用语言影响
S6. 翻译
 可以进一步提问让其使用期望的语言,如中文
可以进一步提问让其使用期望的语言,如中文
如何生成自己的OPENAI_API_KEY
登录地址 => https://platform.openai.com/account/api-keys
[Tips] 若使用付费的GPT4则更佳
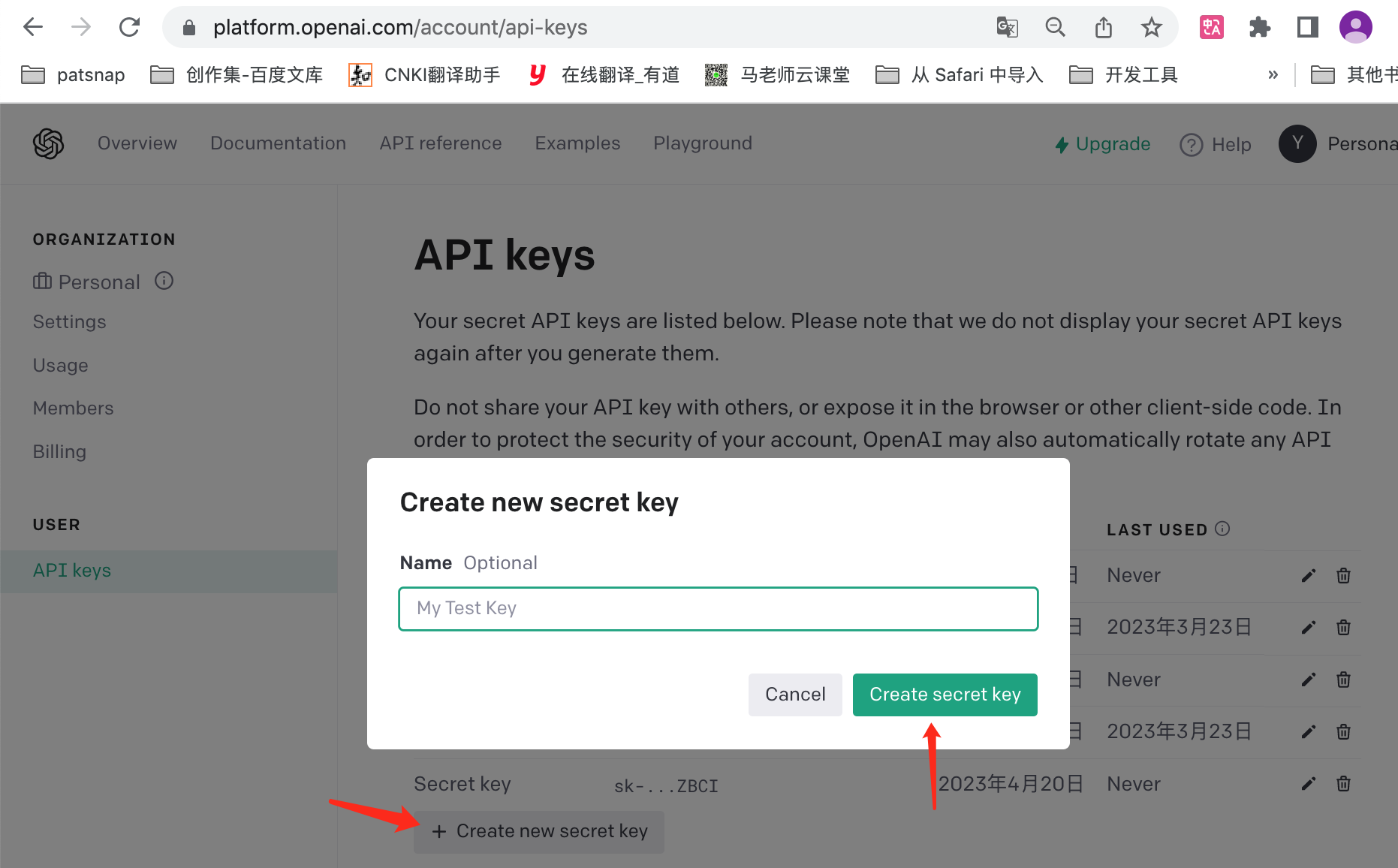 操作示意图
操作示意图
代码执行报错
ModuleNotFoundError: No module named 'langchain.utilities'
报错可能原因:python版本低于3.8
解决:升级到3.8 (我使用的是3.9.4)


 0000
0000

 0001
0001

 0000
0000

 0005
0005- 0000
